
Editorial often becomes one of our big bottlenecks during the end of production. Between trying to keep the clients and creative directors happy and pushing out new shot timings and new cuts; it's really no surprise editorial often feels overwhelmed. Thankfully we finally had the time to help do something about it.
One of the biggest challenges for editorial is pushing out new versions of cuts while making sure everyone gets what they need. Our goal was to make something with very little user interaction that could run continuously in the background, and take away some of that work. We wanted editorial to be able to focus on what they loved again, editing, and everything else happen automatically.
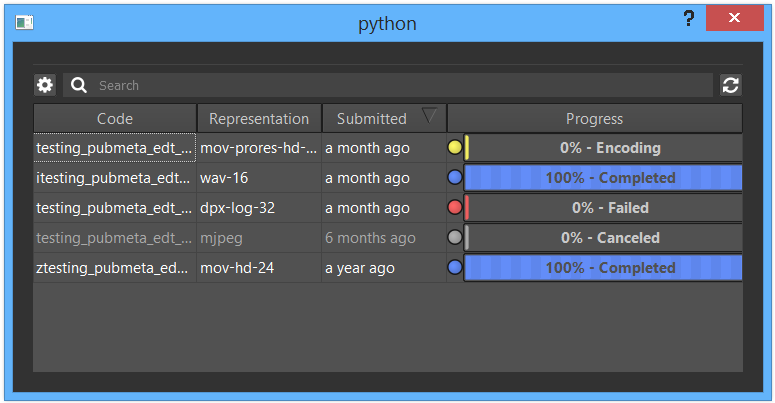
We needed the application to be simple and straight forward and accomplish as many menial and monotonous tasks in the background as possible. Specifically we needed it to do the following things:
- Create job JSON files of each output
- Wait for Media Encoder to finish encoding
- Fix frame padding and start number ( How is custom frame padding still not a feature in Adobe Media Encoder? )
- Add the new output information to the Shotgun Version
- Update shot timings for all involved shots in Shotgun
- Upload a preview to Shotgun
- Embed or Create XMP files for metadata
- Set the status for the version so we know it's ready to use
- Notify animators of the new shot timings
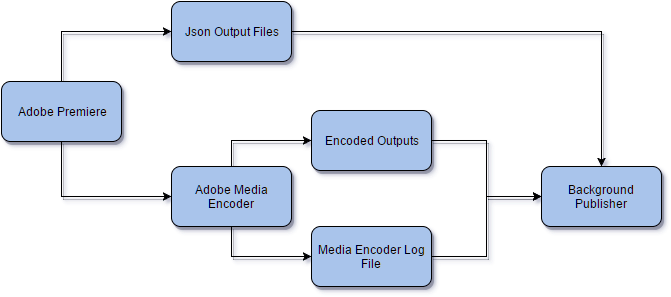
The first thing we needed was easy, just a simple JSON file storing the information we needed that could be exported from premiere. This involved parsing the exported XML file from premiere to get shot timings and other useful information. This came down to two steps:
First, parsing all the clips from the XML:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | def element_to_dict(t):
"""Converts a Preimere etree element to a dict"""
d = {}
d.update({k: v for k, v in t.items()})
d['element'] = t
for c in t.iterchildren():
d[c.tag] = c.text
_children = c.getchildren()
if _children:
data = element_to_dict(c)
if data:
d[c.tag] = data
return d
def parse_clip_elements(path, requirePublish=True):
"""Parses all clip elements from the provided xml path. Each clip element contains a reference to it's xml object."""
with open(path, 'r') as f:
tree = etree.parse(f)
tracks = tree.xpath('/xmeml/sequence/media/video/track')
items = []
for track in tracks:
clipItems = track.findall('clipitem')
items.extend([element_to_dict(x) for x in clipItems])
results = []
for item in items:
# We use logginginfo to connect clips to Shotgun shots, here we filter out clip items that aren't in Shotgun
if 'logginginfo' not in item or item['logginginfo'] is None:
continue
if 'lognote' not in item['logginginfo'] or item['logginginfo']['lognote'] is None:
continue
# We also go ahead and filter out any clips that have no path
if 'file' not in item or item['file'] is None:
continue
if 'pathurl' not in item['file'] or item['file']['pathurl'] is None:
continue
results.append(item)
return results
|
Second, getting a list of updated shots and version from those parsed clips:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | def build_shots_and_versions_from_clip_elements(elements, stripVersion=True):
"""Gets a list of shots and a list of versions from clip elements. Can be piped directly into the shots."""
shots = []
versions = []
for element in elements:
version = json.loads(element['logginginfo']['lognote'])
entity = version['entity']
clip = {
'id': entity['id'],
'type': entity['type'],
}
for key, new_key in [('start', 'edlIn'), ('end', 'edlOut'), ('in', 'cutIn'), ('out', 'cutOut')]:
value = element[key]
try:
value = int(value)
except ValueError:
pass
clip[new_key] = value
if clip['edlIn'] == -1:
clip['edlIn'] = int(element_to_dict(element['element'].getprevious())['start'])
if clip['edlOut'] == -1:
clip['edlOut'] = int(element_to_dict(element['element'].getnext())['end'])
clip['cutIn'] = version['firstFrame'] + clip['cutIn']
clip['cutOut'] = version['firstFrame'] + clip['cutOut']
clip['duration'] = clip['cutOut'] - clip['cutIn']
version = {'id': version['id'], 'type': 'Version'}
shots.append(clip)
versions.append(version)
return shots, versions
|
The most difficult goal to achieve ended up being how to wait for encoding to finish. Adobe Media Encoder, as we soon found out, doesn't have much of an api. The only way we could know when media encoder finished was if we kept premier open and locked up. This was a pretty big problem since it meant editorial would not be able to work on other projects during exports. Thankfully we found a more creative method, parsing the Adobe Media Encoder log file. Stored in the log file is each path, date and time completed, and status; exactly the kind of information we needed:
1 2 3 4 5 6 7 8 | - Source File: S:\...\testing_publishing_77.prproj
- Output File: \\RENDERS\...\testing_pubmeta_Edit_main_mov-hd-24_v010.mov
- Preset Used: shotgun_mov-h264
- Video: 2048x1080 (1.0), 24 fps, Progressive, 00:00:07:07
- Audio: AAC, 320 kbps, 48 kHz, Stereo
- Bitrate: VBR, 1 pass, Target 16.00 Mbps, Max 24.00 Mbps
- Encoding Time: 00:00:14
08/20/2016 08:59:49 PM : File Successfully Encoded
|
Now that we have all of our data and we know encoding has finished, setting Shotgun values and uploading preview videos is just reusing some Shotgun code that already exists. Scaling this up does add some complexity. We add two thread pools, one for scanning the log to check for completion and one for doing the publishing. This way we have two sets of threads, one locked up with publishing from the queue and one free to scan and find new files. The scanning process is called from a QTimer, allowing the main thread to be completely open to gui/user interaction. This means no lock ups or slow downs, even when scaled up to enormous numbers of jobs. A basic flow of the gui is below:
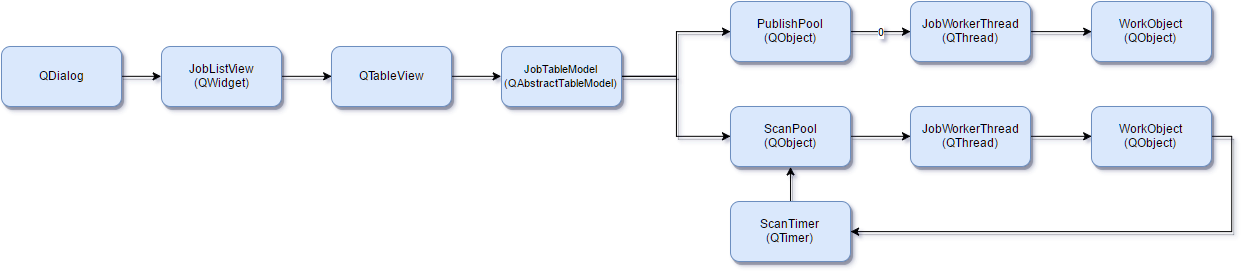
This tool set was something editorial had been needing for awhile. We still have a few things we are working through, but it's already making a big difference. Our latest project had a lot less issues with animators stuck using old incorrect frame ranges because something slipped through editorial. Definitely a fun easy little tool that really made a difference.
